Our Brain's 86 Billion Neurons: Can LLMs Surpass Them?
The human brain, a complex biological system perfected over millions of years of evolution, stands in contrast to Large Language Models (LLMs), the latest achievements in artificial intelligence. Although LLMs demonstrate impressive capabilities in language processing, can they ever surpass the complexity and abilities of the human brain?

The human brain is often considered the most cognitively advanced among mammals, and its size appears significantly larger than what our body size would predict. The number of neurons is generally accepted to play a key role in the brain's computational capacity, yet the common claim that the human brain contains 100 billion neurons and ten times as many glial cells has never been scientifically confirmed. In fact, the precise number of neurons and glial cells in the human brain was unknown until recently.
According to the latest findings, an average adult male brain contains 86.1 ± 8.1 billion neurons and 84.6 ± 9.8 billion non-neuronal cells (glia). Interestingly, only 19% of neurons are located in the cerebral cortex, even though the cortex accounts for 82% of the human brain's mass. This means that the increased size of the human cortex is not accompanied by a proportional increase in the number of cortical neurons.
The ratio of glial cells to neurons in different regions of the human brain is similar to that observed in other primates, and the total cell count aligns with values expected for a primate of human size. These results challenge the widely held view that the human brain has a special composition compared to other primates. Instead, they suggest that the human brain is an isometrically scaled-up version of an average primate brain – essentially, a primate brain adapted to human size.
This realization offers a new perspective, prompting us to reconsider what truly makes human thought and cognitive abilities unique. Today, however, I approach the question from a different angle: can our brain be compared to Large Language Models (LLMs), for instance, in terms of parameter count? Or, despite AI researchers and developers continuously studying our brain and trying to translate its workings into artificial intelligence systems, is any comparison meaningless, simply because one is a chemical system and the other an electronic one? But first, some related background information.
How Are Neurons Counted?
Estimating the number of neurons is a tricky task, as the brain is not uniformly structured. One approach involves counting neurons in a specific brain region and then extrapolating this value to the entire brain. However, this method poses several problems:
-
Uneven Distribution
The density of neurons varies greatly across different parts of the brain. For example, the cerebellum, located at the lower back of the brain, contains about half of all neurons, despite having a significantly smaller volume compared to the rest of the brain. This is because the cerebellum's tiny neurons are responsible for fine-tuning motor coordination and other automated processes. The previously mentioned cerebral cortex – responsible for higher-order thinking – contains larger neurons forming more complex networks. Here, a cubic millimeter contains approximately 50,000 neurons. -
Neuron Visibility
Neurons are packed so densely and intricately interconnected that counting them individually is difficult. A classic solution is the Golgi stain, developed by Camillo Golgi. This technique stains only a small fraction of neurons (usually a few percent), leaving other cells invisible. While this helps obtain a more detailed sample, extrapolating the results still carries uncertainties.
The latest, more accurate estimate is based on an innovative technique. Researchers dissolve the membranes of brain cells, creating a homogeneous mixture – a sort of "brain soup" – where the nuclei of brain cells can be distinguished. Staining these nuclei with different markers allows neurons to be separated from other brain cells, such as glia. This method, often called the isotropic fractionator technique, eliminates errors arising from density differences between brain regions and provides a more accurate result for the entire brain.
Although this new technology significantly reduces the uncertainty of previous estimates, the method still relies on sampling and extrapolation.
How Does the Human Brain Work?
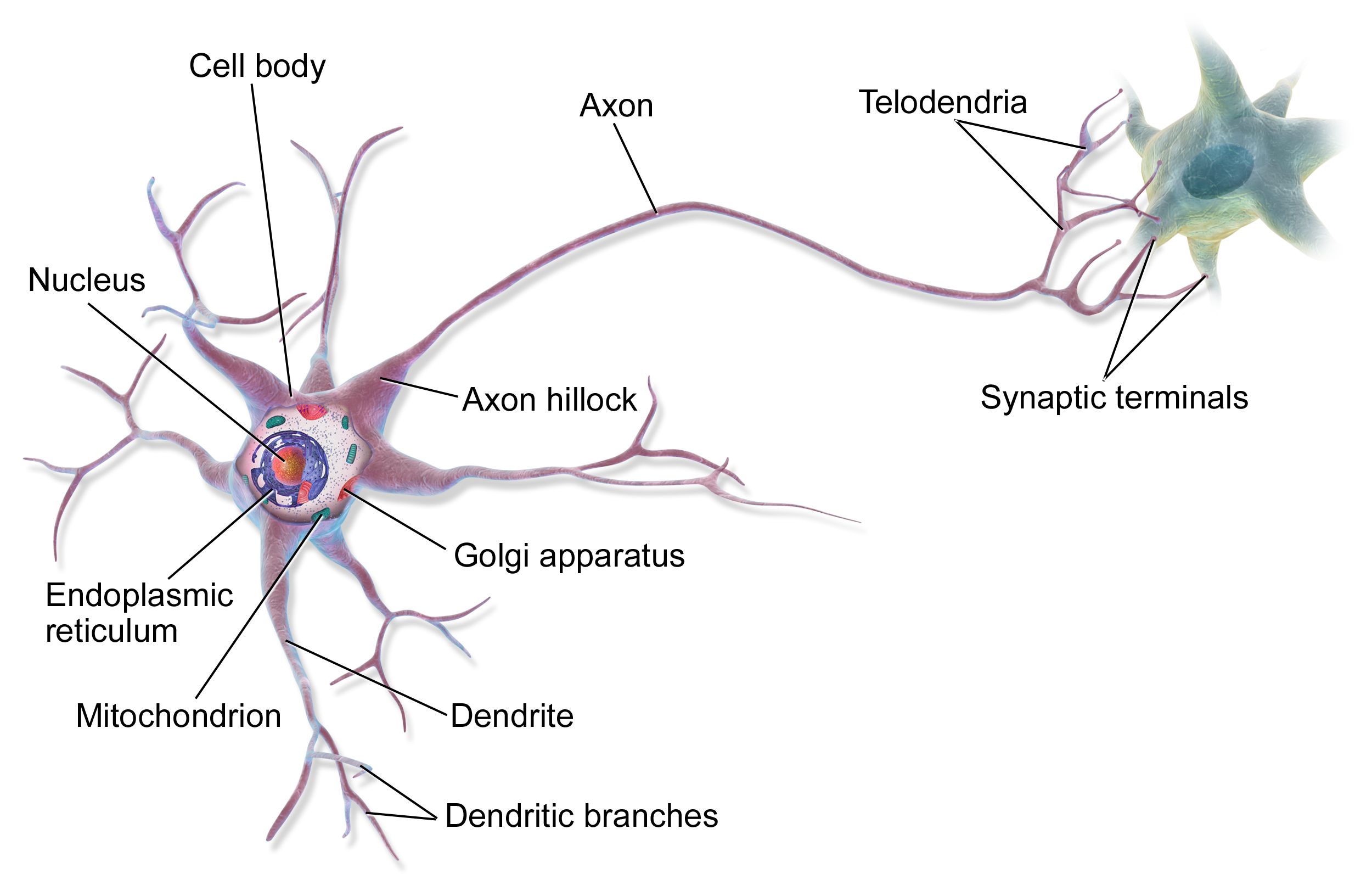
The fundamental building blocks of the brain are neurons, which we now know number around 86 billion in an adult brain. However, they are not all the same – there are many different types of neurons performing distinct functions. Alongside neurons, there are roughly the same number of glial cells, which provide support functions, such as supplying nutrients and participating in immune defense.
The connections between neurons, the synapses, are what make the brain truly special. An average neuron forms about 7,000 synapses with other neurons, resulting in a total of approximately 600-1000 trillion synaptic connections in the brain. These connections are not static – they constantly change, strengthening or weakening during learning processes. This is known as synaptic plasticity.
Source: Wikipedia
Different brain regions are specialized for specific functions (as touched upon earlier). The cerebrum is the center for conscious thought, perception, and motor planning. The cerebellum is the main area for motor coordination and procedural learning. The brainstem regulates basic life functions, while the limbic system is responsible for emotional processing and memory.
Information processing in the brain occurs in parallel – different regions work on different tasks simultaneously. Information is transmitted through a combination of electrical and chemical signals. When a neuron is activated, it sends an electrical impulse (action potential) down its axon, triggering the release of neurotransmitters at the synapses. These chemical messengers then influence the activity of the next neuron.
The brain's energy consumption is remarkably efficient – it uses only about 20 watts, equivalent to the power of an energy-saving light bulb. Despite this, the brain consumes about 20% of the body's total energy expenditure (while making up only 2% of our body mass), indicating how energy-intensive information processing is.
Brain activity is organized not just at the neuronal level. Different frequency brain waves (alpha, beta, theta, delta) can be observed, reflecting the synchronized activity of large groups of neurons. These rhythms play important roles, for example, in memory consolidation and attentional processes.
One of the brain's most crucial properties is its plasticity – its ability to reorganize itself throughout life. This is not only the basis of learning but also allows for partial recovery after injury. Neuroplasticity occurs through various mechanisms, such as the formation of new synapses, the strengthening or weakening of existing connections, and in some cases, even the formation of new neurons (neurogenesis).
Modern research shows that the brain is connected not only to the central nervous system but also interacts closely with the gut (the gut-brain axis) and is significantly influenced by the immune system. This complex network of interactions explains why factors like diet or stress have such a profound impact on cognitive functions.
Science still faces many questions regarding brain function. For instance, we don't yet understand how consciousness arises or precisely how memories are stored and retrieved. Ongoing large-scale brain research projects, such as the Human Brain Project or the BRAIN Initiative, promise further new discoveries in the near future.
How Do Language Models Work?
While the fundamental architecture of human brains is similar, with individual variations observed in structure and function (due to factors like neurodiversity or individual experiences), artificial intelligence language models exhibit a wide spectrum in terms of structure and parameters. These model differences can arise from using different architectures (like transformers versus recurrent networks) or being trained on different datasets. However, there are some areas where they are more or less aligned. I will try to outline these.
Transformer-based language models (like GPT or Llama models) are fundamentally built from transformer blocks (layers), which contain encoder and decoder parts (or often just decoder parts). Each block houses several components performing different tasks. The most important among these are the multi-head self-attention mechanism and the feed-forward neural network layer. Besides these components, layer normalization, dropout, and position encoding also play significant roles. The essence of the self-attention mechanism is that it dynamically learns the relationships between input words, while the feed-forward network performs a non-linear transformation.
When we talk about the parameter count (one of the most crucial determinants of language models, often even included in the model's name), we are actually referring to the sum of the model's learnable weights and biases. These parameters determine how the model processes information and are optimized during the training (learning process). The number of parameters depends on several factors:
-
Number of transformer blocks: Larger models typically contain more transformer blocks. For example, GPT-3's 175 billion parameters [^1] use 96 blocks (layers), while the Llama 2 70-billion parameter version uses 80 blocks. The depth of the blocks significantly impacts the parameter count.
-
Hidden state size: This is a vector representing information within a given block and determines how much information the model can process simultaneously. The larger this number, the more parameters are needed in the transformer blocks.
-
Number of attention heads: Multi-head attention allows the model to analyze the same input from different perspectives. Each attention head requires additional parameters.
Looking at specific numbers: in a typical transformer block, parameters are distributed among:
-
The weight matrices of the attention mechanism (Query, Key, Value matrices)
-
The weights and biases of the feed-forward network
-
The scaling and shifting parameters of layer normalization
-
Parameters for position encoding (for both learned and sinusoidal versions)
An interesting aspect is computational complexity: the computational cost of the self-attention mechanism grows quadratically with the sequence length. This means that although the model has many parameters, not all parameters are active simultaneously during actual processing. Sparse attention techniques attempt to address this issue.
Therefore, parameter count alone is not necessarily a good measure of a model's capabilities. A smaller model with a better architecture can often outperform a larger but less efficient model. Model performance is also evaluated using metrics like accuracy, F1-score, BLEU score, or PERPLEXITY. This is similar to how in the human brain, it's not just the number of neurons or synapses that matters, but also their organization and the quality of the connections between them.
Can the Brain Be Compared to a Language Model Based on Specific Values?
While it might be tempting to gauge the current level of artificial intelligence by comparing its performance and knowledge to our brain, the descriptions above suggest that although the primary source for developing artificial systems is the study of our brain's structure and function (as it's a working example – however trivial that sounds, it's a crucial fact), the comparison is far from straightforward. Directly comparing LLM parameters to either the number of neurons or synapses is not feasible because the two systems are based on fundamentally different operating principles and architectures. However, despite the fundamental differences, some analogies can be drawn between the two systems.
Neurons vs. LLM Layers
-
LLM layers somewhat resemble the brain's hierarchical structure, where information processing occurs at multiple levels. However, in the brain, the hierarchy is more functional and divided into specialized regions, whereas in LLMs, layers represent levels of abstraction.
-
Neurons are locally independent units but globally organized into networks, while LLM layers are globally interdependent through the attention mechanism. Self-attention allows for global information flow within a layer.
Synapses vs. LLM Parameters
-
LLM parameters are similar to synapses in the sense that both influence the strength of information flow, albeit through different mechanisms.
-
Synapses change dynamically and adapt, whereas LLM parameters are static after training. Fine-tuning allows parameters to change again, but this still doesn't match the dynamic nature of synapses. Synaptic strength changes via long-term potentiation (LTP) or long-term depression (LTD), which are dynamic bio-electrochemical processes.
What Better Represents LLM Parameters?
-
Neither neurons nor synapses accurately represent LLM parameters, but the closest analogy is to synapses, as they also regulate connections and the strength of information flow. Using this approach, it's interesting to note that the number of synapses in the brain is orders of magnitude larger (100-1000 trillion synapses compared to 70 billion to potentially over 1 trillion parameters in the largest LLMs).
-
However, synapses are far more complex and dynamic than LLM parameters. Synapses aren't just simple weights; they regulate connections through complex bio-electrochemical processes that change dynamically based on activity and experience.
Why is the Analogy Imprecise?
-
Operational Differences:
-
The brain exhibits biological parallelism and processes continuous signals, while LLMs rely on discrete, digital computations performed by numerical processors (GPUs/TPUs). In the brain, computations are carried out by biochemical processes and electrical signals.
-
-
Learning Mechanism:
-
Brain learning is dynamic and efficient even with little data. Pattern recognition and reinforcement play crucial roles. Human learning is often one-shot or few-shot, enabling generalization from few examples. Reinforcement learning is also important in the brain.
-
LLM training requires massive amounts of data and computational resources. LLMs are less capable of generalizing from few examples.
-
-
Energy Efficiency:
-
The brain is extremely energy-efficient. Training and running LLMs are hugely energy-intensive, orders of magnitude greater than the human brain's energy consumption.
-
-
Representation:
-
Representations in the brain are distributed and dynamic, while in LLMs, they are more like static vectors.
-
The brain is associated with consciousness and subjective experience, which LLMs currently lack.
-
-
Architecture:
-
The brain's hierarchical organization is much more complex and modular, with different regions performing different functions. This modularity is less pronounced in LLMs.
-
Feedback loops play an important role in the brain, whereas this is less characteristic of most LLMs.
-
-
Adaptation and Flexibility:
-
The brain is highly adaptive and flexible due to neuroplasticity, while LLMs are less capable of adapting to changes post-training.
-
The brain can adapt to its environment, a capability less evident in LLMs.
-
-
Emotions and Motivation:
-
Emotions play a vital role in decision-making and learning in the brain, a dimension missing in LLMs.
-
Motivation is crucial for behavior in the brain, another dimension absent in LLMs.
-
Summary
As we've seen, although certain analogies can be drawn between LLM layers and the brain's hierarchical structure, or between LLM parameters and synapses, these analogies are limited. Thus, the question posed in the article's title, "Our Brain's 86 Billion Neurons: Can LLMs Surpass Them?" has no straightforward answer.
The two systems are based on fundamentally different operating principles and architectures. LLMs lack consciousness, subjective experience, and cannot generalize from few examples in the way the brain can.
Future artificial intelligence research will likely focus on further developing LLM capabilities, potentially bringing them closer to how the human brain functions. This might include developing more dynamic learning mechanisms, greater energy efficiency, better generalization abilities, and perhaps implementing some form of consciousness. A deeper understanding of brain function could help develop more efficient and intelligent AI systems.
However, it's important to remember that LLMs are not copies of the human brain but represent a different path towards achieving intelligence. Understanding the differences between the two systems is essential for using the opportunities offered by artificial intelligence responsibly and effectively. In the future, the synergy between neuroscience and artificial intelligence could open new horizons for both fields.
Sources:
- https://pubmed.ncbi.nlm.nih.gov/19226510/
- https://www.nature.com/scitable/blog/brain-metrics/are_there_really_as_many/
- https://www.sciencealert.com/scientists-quantified-the-speed-of-human-thought-and-its-a-big-surprise
- https://www.ndtv.com/science/human-brains-are-not-as-fast-as-we-previously-thought-study-reveals-7323078
- https://www.sciencealert.com/physics-study-overturns-a-100-year-old-assumption-on-how-brains-work
[^1]: Note: While 175B is the widely cited figure for the original GPT-3, parameter counts for newer models or specific versions can vary and are sometimes not officially disclosed.