Понимание архитектуры Mixture of Experts (MoE)
Mixture of Experts (MoE) – это архитектура машинного обучения, основанная на принципе «разделяй и властвуй». Ее ключевая идея – разбить крупную модель на ряд более мелких, специализированных подмоделей, которые называются «экспертами». Каждый «эксперт» специализируется на решении определенной задачи или обработке конкретного набора данных.

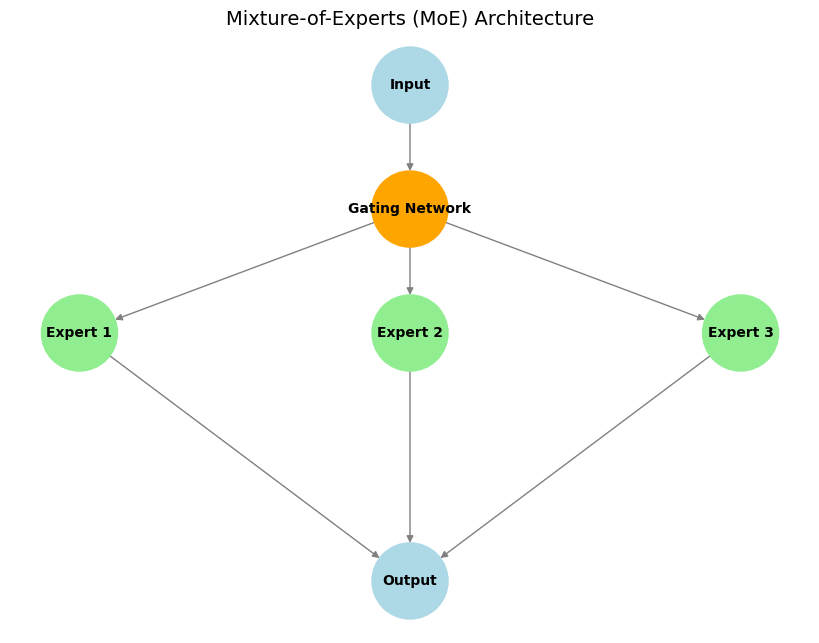
Основные компоненты:
- Эксперты: Это отдельные подсети (часто идентичные по архитектуре, но с разными весами), которые обучаются специализироваться на обработке различных типов входных данных или выполнении определенных подзадач.
- Стробирующая сеть: Она действует как «регулировщик движения». Для заданного входного сигнала стробирующая сеть решает, какие эксперты наиболее подходят и должны быть активированы для его обработки, обеспечивая эффективное использование вычислительных ресурсов.
- Разреженная активация экспертов: Ключевая особенность MoE. Только небольшое подмножество экспертов (часто всего один или два) активируются стробирующей сетью для каждого входного токена. Это приводит к значительной вычислительной эффективности и экономии памяти по сравнению с плотными моделями, где вся сеть обрабатывает каждый вход.
Наглядный пример:
Представьте себе команду специалистов (например, математика, лингвиста и программиста), работающих вместе над сложными задачами. Когда поступает вопрос, например, «Напиши программу!», руководитель группы (стробирующая сеть) выбирает программиста (соответствующего эксперта) для выполнения задачи. Если же поступает математическая проблема, то ведущим становится математик. Таким образом, каждый эксперт сосредотачивается только на том, что он делает лучше всего, и команда работает эффективно.
Преимущества:
- Вычислительная эффективность: Для каждого входного сигнала активируются только соответствующие эксперты, что значительно снижает вычислительные затраты (FLOPs) во время инференса по сравнению с плотной моделью с аналогичным общим количеством параметров.
- Масштабируемость: Модели можно масштабировать до очень большого количества параметров, добавляя больше экспертов, без пропорционального увеличения вычислительных затрат на каждый входной токен.
- Специализация и производительность: Отдельные эксперты могут стать узкоспециализированными, что потенциально приводит к лучшей производительности при решении разнообразных задач по сравнению с единой монолитной моделью.
Пример: Mixtral 8x7B
Известным примером является модель Mixtral 8x7B. В каждом слое MoE имеется 8 отдельных «экспертных» нейронных сетей прямого распространения, каждая из которых насчитывает около 7 миллиардов параметров. Однако для обработки каждого входного токена стробирующая сеть обычно выбирает только 2 лучших эксперта. Это означает, что, хотя модель имеет большое общее количество параметров (концептуально, 8 экспертов 7 миллиардов параметров на эксперта в этих слоях, что значительно влияет на общий размер), активное количество параметров, используемых для вычислений на каждом шаге, намного меньше (ближе к 2 7 миллиардам параметров). Такая разреженная активация делает MoE особенно эффективной для создания чрезвычайно больших, но вычислительно управляемых моделей, особенно больших языковых моделей (ББМ или LLM), где оптимизация стоимости инференса и требований к памяти имеет решающее значение.
Заключение
Архитектура Mixture of Experts предлагает мощный подход к эффективному масштабированию моделей машинного обучения. Используя специализированные подмодели и разреженную активацию, MoE позволяет разрабатывать передовые модели, такие как Mixtral, которые расширяют границы производительности ИИ, одновременно справляясь с вычислительными требованиями.