Comprendiendo la Arquitectura de Mixture of Experts (MoE)
Mixture of Experts (MoE) es una arquitectura de aprendizaje automático que sigue el principio de "divide y vencerás". La idea básica es dividir un modelo grande en varios submodelos especializados más pequeños – llamados "expertos" – cada uno especializado en una tarea específica o subconjunto de los datos.

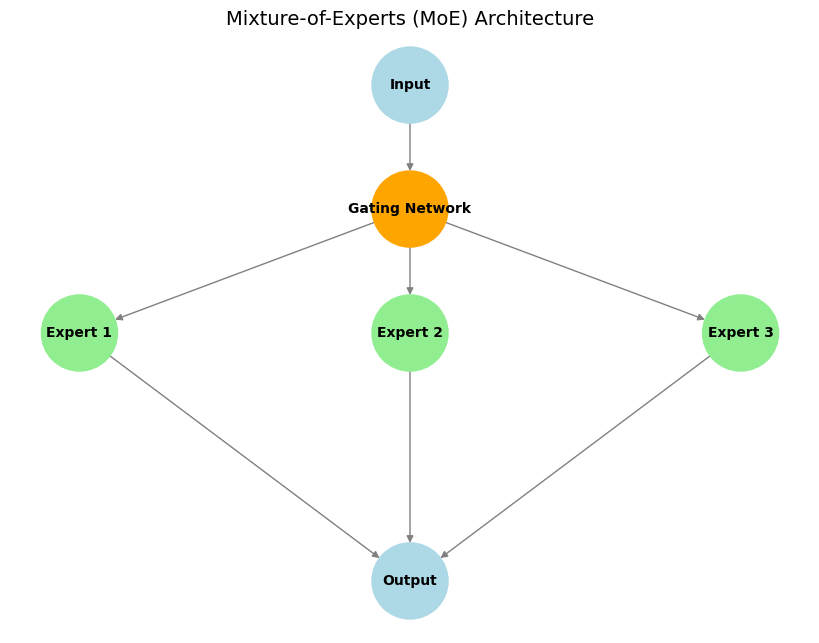
Componentes Principales:
- Expertos: Estas son subredes distintas (a menudo idénticas en arquitectura pero con diferentes pesos) que aprenden a especializarse en el procesamiento de diferentes tipos de entrada o en la realización de subtareas específicas.
- Red de Gating: Esta actúa como un "controlador de tráfico". Para una entrada dada, la red de gating decide qué experto(s) son los más adecuados y deben activarse para procesarla, asegurando que los recursos computacionales se enfoquen de manera efectiva.
- Activación Dispersa de Expertos: Una característica clave de MoE. Solo un pequeño subconjunto de expertos (a menudo solo uno o dos) son activados por la red de gating para cualquier token de entrada dado. Esto conduce a una eficiencia computacional y de memoria significativa en comparación con los modelos densos donde toda la red procesa cada entrada.
Ejemplo Ilustrativo:
Imagina un equipo de especialistas (por ejemplo, un matemático, un lingüista y un programador) trabajando juntos en problemas complejos. Cuando llega una pregunta, como "¡Escribe un programa!", el líder del equipo (la red de gating) selecciona al programador (el experto relevante) para manejar la tarea. Sin embargo, si reciben un problema matemático, el matemático toma la iniciativa. De esta manera, cada experto se enfoca solo en lo que mejor hace, y el equipo opera de manera eficiente.
Ventajas:
- Eficiencia Computacional: Solo los expertos relevantes se activan para cada entrada, reduciendo significativamente el costo computacional (FLOPs) durante la inferencia en comparación con un modelo denso de un recuento de parámetros totales similar.
- Escalabilidad: Los modelos se pueden escalar a un número muy grande de parámetros agregando más expertos, sin aumentar proporcionalmente el costo computacional para cada token de entrada.
- Especialización y Rendimiento: Los expertos individuales pueden volverse altamente especializados, lo que podría conducir a un mejor rendimiento en diversas tareas en comparación con un solo modelo monolítico.
Ejemplo: Mixtral 8x7B
Un ejemplo bien conocido es el modelo Mixtral 8x7B. En cada capa MoE, hay 8 redes neuronales feed-forward "expertas" distintas, cada una con aproximadamente 7 mil millones de parámetros. Sin embargo, para procesar cada token de entrada, la red de gating normalmente selecciona solo los 2 expertos principales. Esto significa que si bien el modelo tiene un gran número total de parámetros (conceptualmente, 8 expertos 7B parámetros/experto en esas capas, contribuyendo significativamente al tamaño general), el número activo de parámetros utilizados para el cálculo en cualquier paso dado es mucho menor (más cerca de 2 7B parámetros). Esta activación dispersa hace que MoE sea particularmente eficaz para construir modelos extremadamente grandes pero computacionalmente manejables, especialmente modelos de lenguaje grandes (LLM), donde optimizar el costo de inferencia y los requisitos de memoria es crucial.
Conclusión
La arquitectura Mixture of Experts ofrece un enfoque poderoso para escalar modelos de aprendizaje automático de manera eficiente. Al aprovechar submodelos especializados y la activación dispersa, MoE permite el desarrollo de modelos de última generación como Mixtral que superan los límites del rendimiento de la IA al tiempo que gestionan las demandas computacionales.