理解专家混合(MoE)架构
3 阅读时间
专家混合 (MoE) 是一种遵循“分而治之”原则的机器学习架构。其基本思想是将大型模型分解为若干较小的、专门的子模型——称为“专家”——每个专家专门处理特定的任务或数据子集。

来源: 作者原创
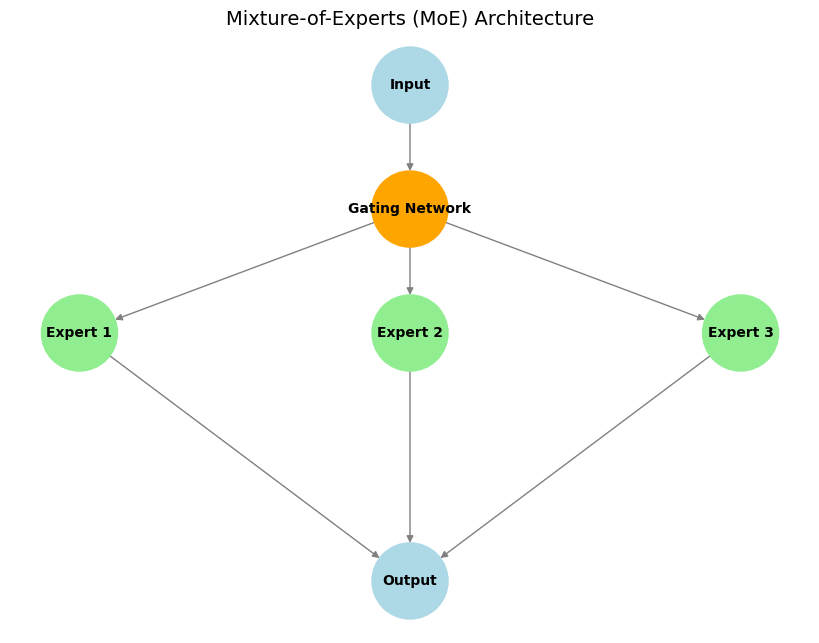
主要组成部分:
- 专家: 这些是不同的子网络(通常架构相同但权重不同),它们学习专门处理不同类型的输入或执行特定的子任务。
- 门控网络: 这充当“交通控制器”。对于给定的输入,门控网络决定哪个或哪些专家最适合并应被激活以处理该输入,从而确保计算资源得到有效集中。
- 稀疏专家激活: 这是 MoE 的一个关键特征。对于任何给定的输入令牌,只有一小部分专家(通常只有一个或两个)被门控网络激活。与整个网络处理每个输入的密集模型相比,这带来了显着的计算和内存效率。
示例说明:
想象一下一个专家团队(例如,数学家、语言学家和程序员)共同解决复杂问题。当收到诸如“编写程序!”之类的问题时,团队负责人(门控网络)会选择程序员(相关专家)来处理该任务。但是,如果他们收到一个数学问题,数学家将带头。这样,每位专家只专注于他们最擅长的工作,团队才能高效运作。
优势:
- 计算效率: 对于每个输入,仅激活相关的专家,与参数总数相似的密集模型相比,显着降低了推理期间的计算成本(FLOP)。
- 可扩展性: 可以通过添加更多专家来将模型扩展到非常大的参数量,而不会按比例增加每个输入令牌的计算成本。
- 专业化与性能: 与单一的单体模型相比,各个专家可以变得高度专业化,从而可能在各种任务上获得更好的性能。
示例:Mixtral 8x7B
一个著名的例子是 Mixtral 8x7B 模型。在每个 MoE 层中,有 8 个不同的“专家”前馈网络,每个网络大约有 70 亿个参数。但是,为了处理每个输入令牌,门控网络通常仅选择前 2 名专家。这意味着,虽然该模型具有大量的总参数(概念上,在这些层中有 8 个专家 70 亿参数/专家,这对整体大小做出了重大贡献),但在任何给定步骤中用于计算的活动参数数量要小得多(接近 2 70 亿参数)。这种稀疏激活使 MoE 在构建极其庞大但计算上可管理的模型方面特别有效,尤其是大型语言模型 (LLM),在这些模型中,优化推理成本和内存需求至关重要。
结论
专家混合架构为高效扩展机器学习模型提供了一种强大的方法。通过利用专门的子模型和稀疏激活,MoE 使得像 Mixtral 这样的最先进模型的开发成为可能,这些模型在管理计算需求的同时,突破了 AI 性能的界限。