Die Mixture-of-Experts (MoE) Architektur verstehen
Mixture of Experts (MoE) ist eine Machine-Learning-Architektur, die dem Prinzip „Teile und herrsche“ folgt. Die Grundidee besteht darin, ein großes Modell in mehrere kleinere, spezialisierte Submodelle – sogenannte „Experten“ – zu unterteilen, von denen sich jeder auf eine bestimmte Aufgabe oder einen bestimmten Datensatz spezialisiert.

Hauptkomponenten:
- Experten: Dies sind separate Subnetzwerke (oft identisch in der Architektur, aber mit unterschiedlichen Gewichtungen), die lernen, sich auf die Verarbeitung verschiedener Eingabetypen oder die Ausführung spezifischer Teilaufgaben zu spezialisieren.
- Gating-Netzwerk: Dieses fungiert als „Verkehrsleiter“. Für eine bestimmte Eingabe entscheidet das Gating-Netzwerk, welche Experten am besten geeignet sind und aktiviert werden sollten, um diese zu verarbeiten, wodurch sichergestellt wird, dass die Rechenressourcen effektiv eingesetzt werden.
- Sparse Expertenaktivierung: Ein Hauptmerkmal von MoE. Nur ein kleiner Teil der Experten (oft nur ein oder zwei) wird vom Gating-Netzwerk für ein gegebenes Eingabe-Token aktiviert. Dies führt zu einer erheblichen Rechen- und Speichereffizienz im Vergleich zu dichten Modellen, bei denen das gesamte Netzwerk jede Eingabe verarbeitet.
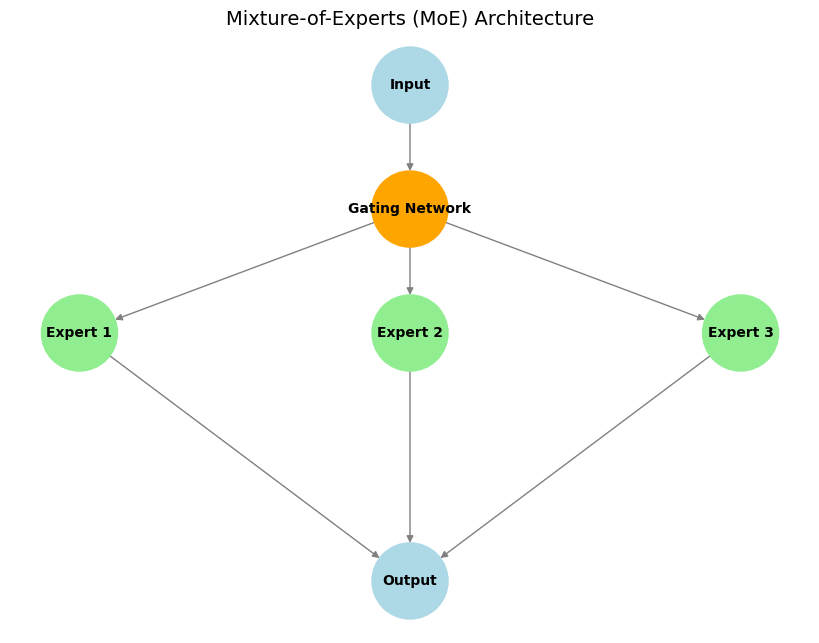
Illustratives Beispiel:
Stellen Sie sich ein Team von Spezialisten vor (z. B. ein Mathematiker, ein Linguist und ein Programmierer), die zusammen an komplexen Problemen arbeiten. Wenn eine Frage eintrifft, wie z. B. „Schreibe ein Programm!“, wählt der Teamleiter (das Gating-Netzwerk) den Programmierer (den relevanten Experten) aus, um die Aufgabe zu übernehmen. Wenn sie jedoch ein mathematisches Problem erhalten, übernimmt der Mathematiker die Führung. Auf diese Weise konzentriert sich jeder Experte nur auf das, was er am besten kann, und das Team arbeitet effizient.
Vorteile:
- Recheneffizienz: Nur die relevanten Experten werden für jede Eingabe aktiviert, wodurch die Rechenkosten (FLOPs) während der Inferenz im Vergleich zu einem dichten Modell mit ähnlicher Gesamtparameteranzahl erheblich reduziert werden.
- Skalierbarkeit: Modelle können durch Hinzufügen weiterer Experten auf eine sehr große Anzahl von Parametern skaliert werden, ohne die Rechenkosten für jedes Eingabe-Token proportional zu erhöhen.
- Spezialisierung & Leistung: Einzelne Experten können sich hochgradig spezialisieren, was potenziell zu einer besseren Leistung bei vielfältigen Aufgaben im Vergleich zu einem einzelnen monolithischen Modell führt.
Beispiel: Mixtral 8x7B
Ein bekanntes Beispiel ist das Mixtral 8x7B-Modell. In jeder MoE-Schicht gibt es 8 verschiedene „Experten“-Feed-Forward-Netzwerke mit jeweils etwa 7 Milliarden Parametern. Für die Verarbeitung jedes Eingabe-Tokens wählt das Gating-Netzwerk jedoch in der Regel nur die Top-2-Experten aus. Dies bedeutet, dass das Modell zwar eine große Gesamtanzahl an Parametern aufweist (konzeptionell 8 Experten 7 Milliarden Parameter/Experte in diesen Schichten, was erheblich zur Gesamtgröße beiträgt), die aktive Anzahl der Parameter, die für die Berechnung in jedem Schritt verwendet werden, jedoch viel geringer ist (näher an 2 7 Milliarden Parametern). Diese spärliche Aktivierung macht MoE besonders effektiv für den Aufbau extrem großer, aber rechentechnisch handhabbarer Modelle, insbesondere großer Sprachmodelle (LLMs), bei denen die Optimierung der Inferenzkosten und des Speicherbedarfs von entscheidender Bedeutung ist.
Fazit
Die Mixture-of-Experts-Architektur bietet einen leistungsstarken Ansatz zur effizienten Skalierung von Machine-Learning-Modellen. Durch die Nutzung spezialisierter Submodelle und spärlicher Aktivierung ermöglicht MoE die Entwicklung hochmoderner Modelle wie Mixtral, die die Grenzen der KI-Leistung verschieben und gleichzeitig den Rechenaufwand bewältigen.