Understanding the Mixture of Experts (MoE) Architecture
Mixture of Experts (MoE) is a machine learning architecture that follows the "divide and conquer" principle. The basic idea is to break down a large model into several smaller, specialized sub-models – called "experts" – each specializing in a specific task or subset of the data.

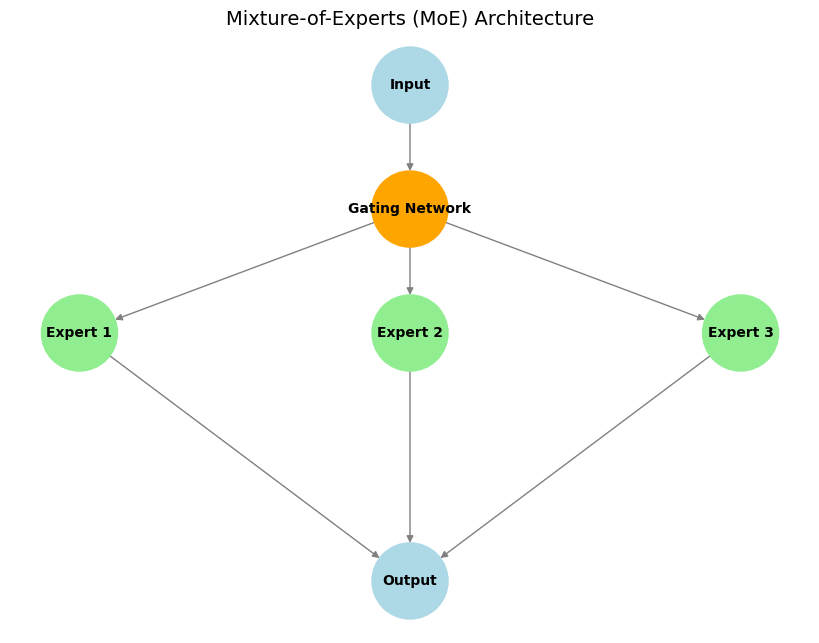
Main Components:
- Experts: These are distinct sub-networks (often identical in architecture but with different weights) that learn to specialize in processing different types of input or performing specific sub-tasks.
- Gating Network: This acts as a "traffic controller". For a given input, the gating network decides which expert(s) are most suitable and should be activated to process it, ensuring that computational resources are focused effectively.
- Sparse Expert Activation: A key feature of MoE. Only a small subset of experts (often just one or two) are activated by the gating network for any given input token. This leads to significant computational and memory efficiency compared to dense models where the entire network processes every input.
Illustrative Example:
Imagine a team of specialists (e.g., a mathematician, a linguist, and a programmer) working together on complex problems. When a question arrives, such as "Write a program!", the team leader (the gating network) selects the programmer (the relevant expert) to handle the task. If, however, they receive a mathematical problem, the mathematician takes the lead. This way, each expert focuses only on what they do best, and the team operates efficiently.
Advantages:
- Computational Efficiency: Only the relevant experts are activated for each input, significantly reducing the computational cost (FLOPs) during inference compared to a dense model of similar total parameter count.
- Scalability: Models can be scaled to a very large number of parameters by adding more experts, without proportionally increasing the computational cost for each input token.
- Specialization & Performance: Individual experts can become highly specialized, potentially leading to better performance on diverse tasks compared to a single monolithic model.
Example: Mixtral 8x7B
A well-known example is the Mixtral 8x7B model. In each MoE layer, there are 8 distinct "expert" feed-forward networks, each with approximately 7 billion parameters. However, for processing each input token, the gating network typically selects only the top 2 experts. This means that while the model has a large *total* number of parameters (conceptually, 8 experts * 7B parameters/expert in those layers, contributing significantly to the overall size), the *active* number of parameters used for computation at any given step is much smaller (closer to 2 * 7B parameters). This sparse activation makes MoE particularly effective for building extremely large yet computationally manageable models, especially large language models (LLMs), where optimizing inference cost and memory requirements is crucial.
Conclusion
The Mixture of Experts architecture offers a powerful approach to scaling machine learning models efficiently. By leveraging specialized sub-models and sparse activation, MoE enables the development of state-of-the-art models like Mixtral that push the boundaries of AI performance while managing computational demands.





